Using GRPO to Learn Chess
Or: Teaching LLMs chess, the hard way
In 2021, I really really wanted a chess engine for my high school CS class final project. Instead of coding alpha-beta tree search like a sane person, I decided to try out that fancy new Reinforcement Learning thing I had heard about in the news (as any ambitious high school freshman would).
I tried a bunch of stuff, none of which worked that well. But although I never got any policy better than random, I had one, fairly clever idea (at least for a ninth-grader). From the slides,

So who says chess can’t be learned like a natural language, one move at a time?
Nobody, nowadays.
Since 2021, plenty of the greats have talked LLMs into playing chess. From Carlini, Dynomight prompting API-called models with PGN strings, to Ruoss, Schultz training transformers to play chess at vastly superhuman levels using various levels of search.
However, all of these works strike me as cool, but missing the point. I don’t want a model that gives me the best next move. Stockfish can do that. I want a language model something that thinks about the game in natural language. I want to see the model talk about the push and pull of the game, describing the thought process behind moves
I’m older and wiser now; despite being a lot worse at chess compared to when I was a ninth grader. So let’s see if I can do better.
RL is smart, 3B Models are stupid
The game plan here is simple, we use GRPO, a technique for training language models using reinforcement learning. There are plenty of other algorithms, that work just as well when combined with verifiable rewards (like ppo), I won’t go into the details here, there are plenty of better explainers online than something I could do. I was pretty excited to try this algorithm on verifiable domains other than math competitions, and chess was the perfect fit.
We can separate the design into a few pieces. For the model, I just grabbed llama-3.2-3b (the qwen models are great, but I didn’t want to implement language rewards, and the chains of thought were quite multilingual).
From there, there are two major design decisions, prompting and reward shaping.
Prompt: Usually, people prompt models just with a list of moves. This makes the life of the model pretty difficult, as it needs to keep track of the board state by itself. Instead, one could use a board state representation, and pass it into the model directly. Instead of using FEN (which tokenizers hate), we give the model the board, the location of all the pieces, as well as all legal moves (in SAN notation).
Reward Shaping:
Now, we have to determine how we reward the model, based on the moves it makes. In the style of past work, we combine a bunch of rewards.
- 2 formatting-based rewards, to make sure the model outputs <think></think><answer></answer>
- One for awarding legal moves
- One for move quality: for this, we take the difference in stockfish evaluation before and after the move. Seeking to push this towards zero is equivalent to a smooth version of “play the best move.” Notably, this is where all the knowledge of chess strategy comes from. Essentially, we are “distilling stockfish” into the model.
So if you train a model like this, what happens?
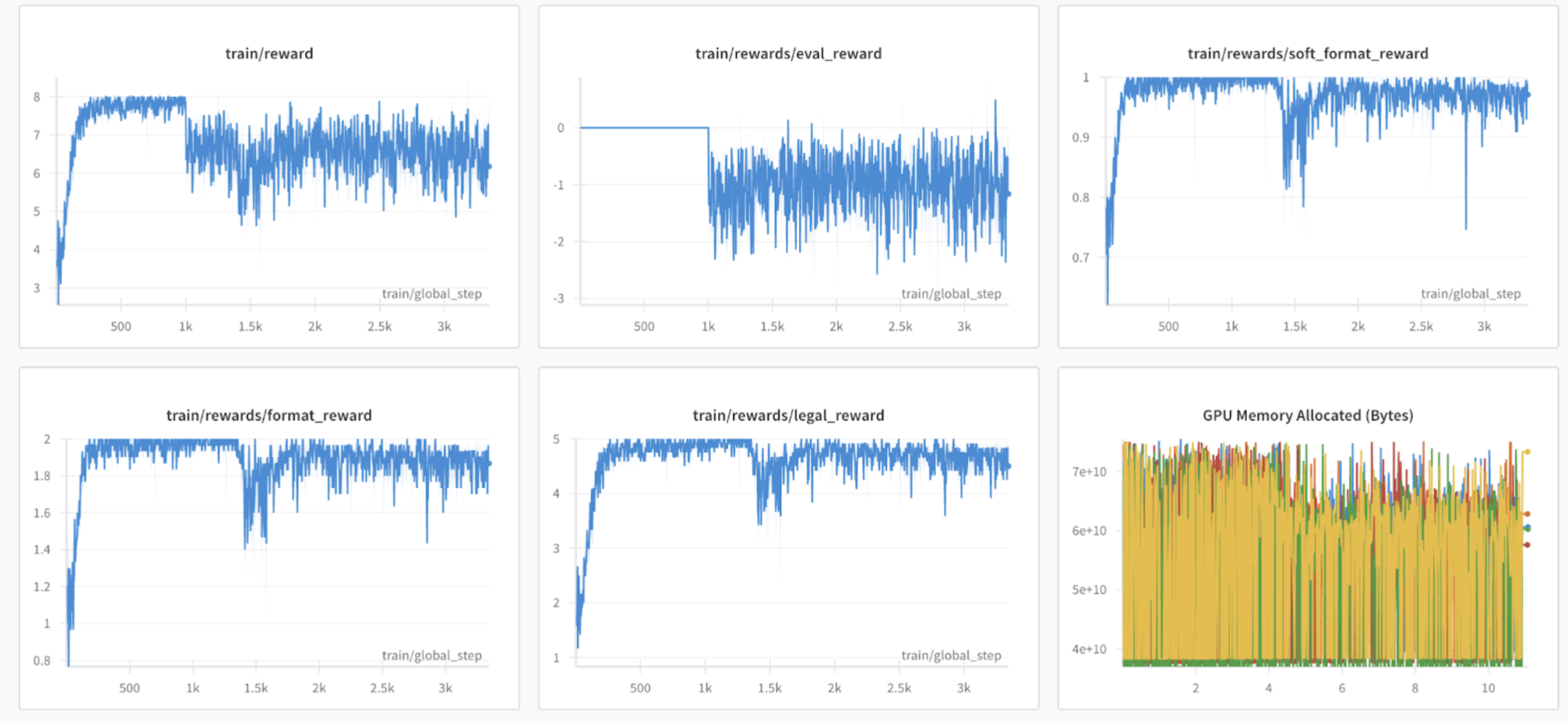
The reward goes up! Wait a minute, I give it all the legal moves, has it learned to do anything?
Huh! It seems like its learned to play moves pretty quickly, but look, the eval reward is quite still. That’s weird, lets check the policy itself. What does it output?
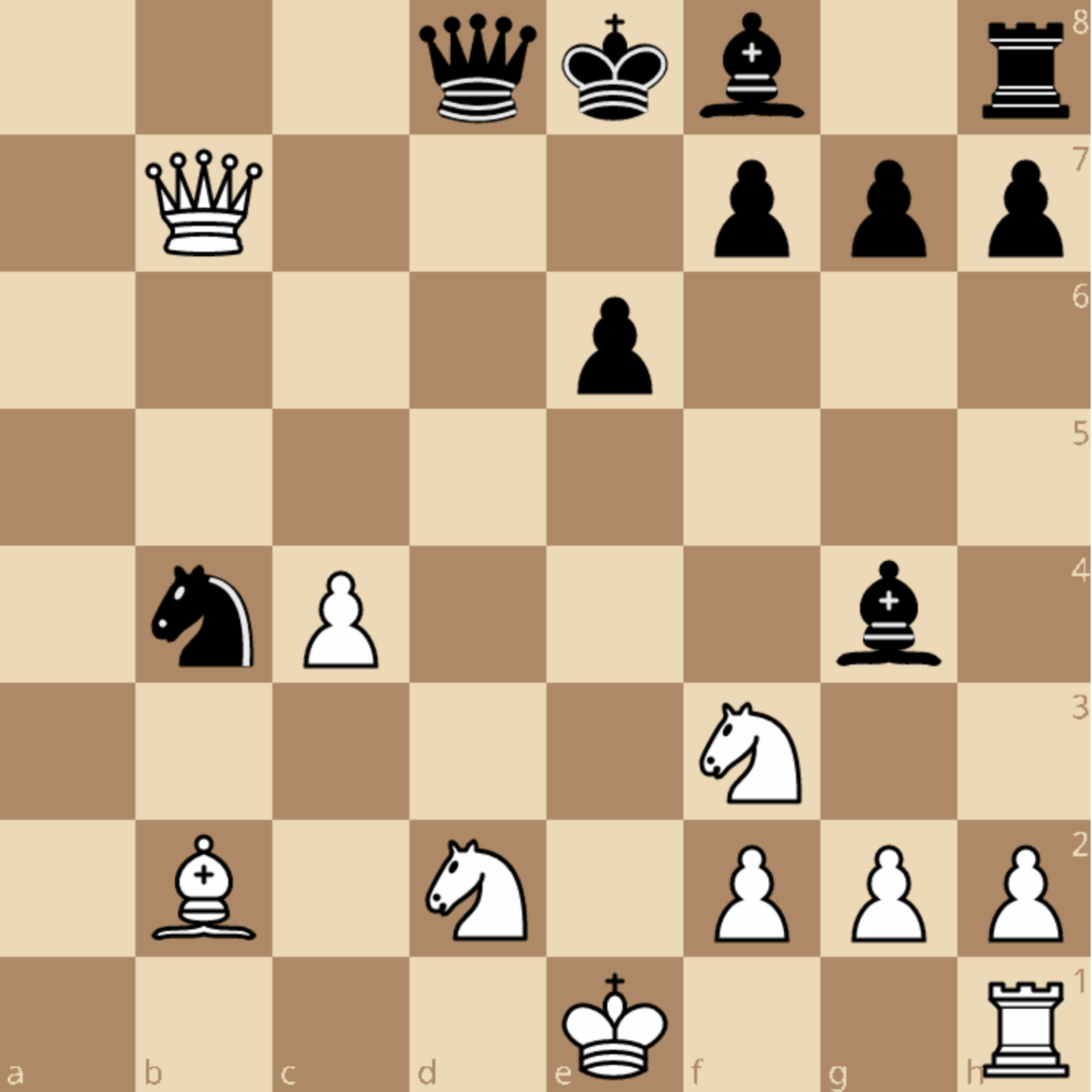
I’m looking for a move that puts pressure on Black’s position and prepares to develop other pieces. I notice that Black’s King is somewhat exposed on e8, and I’d like to take advantage of that.
Answer: a5

I'm looking for a move that puts pressure on Black's position and prepares to develop other pieces. I notice that Black's King is somewhat exposed on g8, and I'd like to take advantage of that.
Answer: cxd6
I'm looking for a move that puts pressure on Black's position and prepares to develop other pieces. I notice that Black's King is somewhat exposed on g8, and I'd like to take advantage of that.
Answer: cxd6
You get the point. It doesn’t really learn to do anything interesting. It learned to play legal moves, after we told it all the legal moves, as well as make up some bullshit about king safety on g8. Classic Mode collapse.
Q: How do we fix it?
A: Stronger Priors Over Chess.
It’s well known that RL isn’t magic. The “prior”, or the original model, has a ton of influence over the results. In fact, some people are attributing the “aha” moment to cognitive behaviors present in the model before RL fine-tuning. My prior was pretty crappy, what if we improved it? 2 Main Changes:
- Scaling Up: 3B models are kinda stupid a lot of the time, 8B models are smarter, a no-brainer, although annoying to set up (TRL has a lot of mem leaks).
- SFT: I trained the model on a synthetic dataset of “fake COT” from ChatGPT-3.5-instruct, filtered using stockfish to only the chains of thought which ended in good moves. GPT-4 base has better output, but was prohibitively expensive. This helped the “style” of the model a lot. I also told it that it was playing against Magnus, just ‘cause.
Thus, I got a model which was maybe halfway decent. However, we can still improve a bunch about the RL pipeline, and I did. Here are some highlights:
- Added a “good move reward”, a 0/1 accuracy indicator if the move lost fewer than 80 cp below optimal
- Edited eval reward to be less noisy, relative based on position evaluation
- Sent batch size TO THE MOON, I found that chess is super high variance between the positions, so I used a kinda insane set of params (batch size 4, 4 training GPUs, 64x gradient accumulation, so total is 1024 positions per training step). As you can see its still super noisy, shrug.
There are some system details related to avoiding the dreaded OOM, but around 40 hours of training later, we got this!
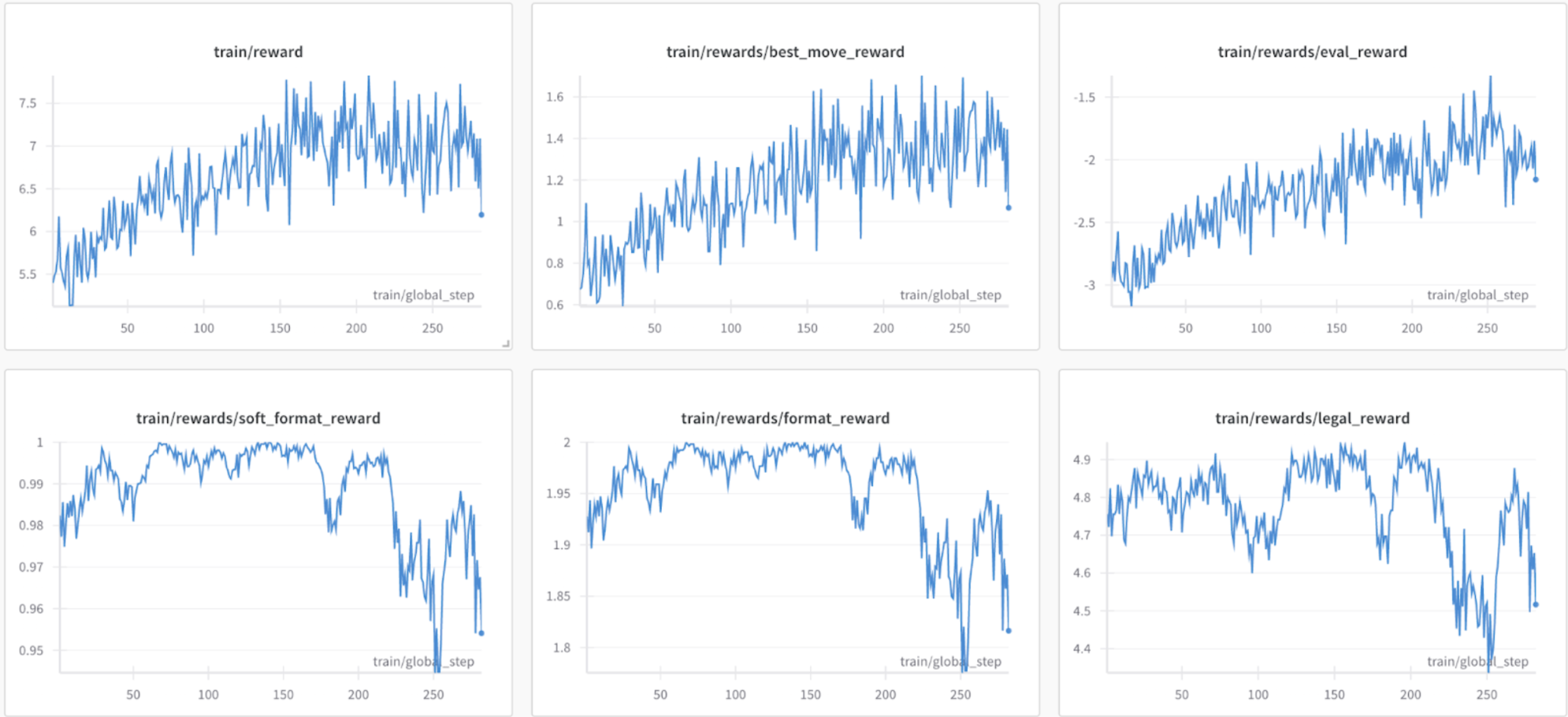 Training went well! “Good move” reward and eval reward went up, by a nontrivial margin. I stopped training here, cause stuff was plateauing atp, and I didn’t wanna break the model.
Training went well! “Good move” reward and eval reward went up, by a nontrivial margin. I stopped training here, cause stuff was plateauing atp, and I didn’t wanna break the model.
The Burning Question: How Well Does it Play?
As we did during training, we can measure the quality of an engine via eval deltas (before and after a move is made, measured in pawns of advantage). Let’s compare it against a pretty weak baseline, stockfish 15 NNUE with search depth capped at 5.
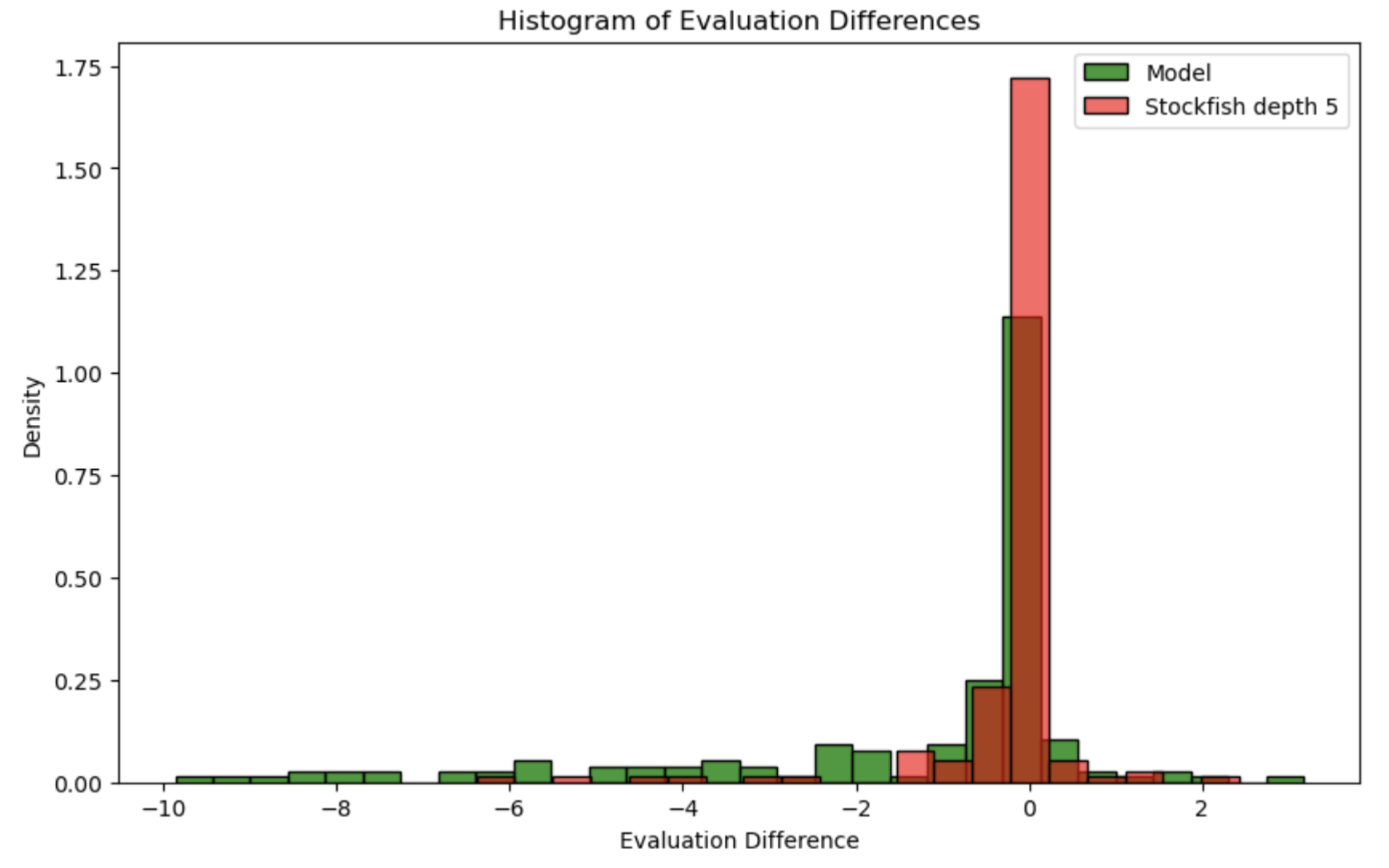 It’s pretty clearly worse in most positions than even this weak baseline.
It’s pretty clearly worse in most positions than even this weak baseline.
However, evals don’t tell the full story. Everyone knows that the best way to test a model is vibes. So I made it play one of my friends (1000 chess.com ELO). The results, well they weren’t spectacular.
Link to the game (engine is white): https://lichess.org/study/Hz1W1joq
Link to reasoning chains. game text
Truly a tragedy indeed. The model never gets off the ground, despite playing plausible-looking moves, it gets flattened by a fairly weak player (no offense Thomas).
However, if you close your eyes and ignore the board, don’t the reasoning chains look so plausible? Here’s a sample:

<think>
In this position, I have a material advantage with a queen and a bishop against Magnus Carlsen’s rook and queen. However, his pieces are more actively placed on the board. My pieces are more centralized, but his are more aggressive. I need to be careful with my move selection to maintain my advantage and not allow any counterplay from Magnus. Looking at the legal moves, I need to be cautious as some moves could potentially expose my king to attacks or weaken my position. Moves like Be2, Bd1, and Qd3 seem like passive moves that don’t actively improve my position. Moves like Qb2, Qc1, and Qb1 are also a bit passive and don’t apply much pressure on Magnus’s position. On the other hand, moves like Qd2, Qe2, and Qb3 are more active and look to control more space on the board. Qxb3 is particularly interesting as it attacks Magnus’s rook on b3 and also indirectly puts pressure on the black king on g7. Another move to consider is Kf1, which moves the king to a safer square, connecting the rooks, and prepares for potential pawn breaks in the center with moves like e5. After considering all the options, I believe the most active move that maintains pressure and potentially creates opportunities for me in the future is Qxb3.
</think>
<answer>Qxb3</answer>
I just can’t help but feel that we aren’t far from El Dorado.
My Next Steps.
As you can see, the model is still quite stupid. Its reasoning chains are short, and it makes horrific blunders nearly half the time. To push this forward, I’m excited about a couple directions.
1. Better SFT datasets: I think this is the main one. I’m a massive fan of my rejection sampling approach to generating reasoning chains, but GPT-3.5 is kinda stupid. I would love to use Gemini Thinking API for this, but the rate limits are pretty prohibitive. I do wonder how the authors of s1 got around this. If I can do that, I think my poor 8b will begin to fly. I would be su
2. Better RL Environment: Currently, the model plays a lot of passive “safe” moves. I think part of this is due to the reward environment: it’s pretty heavily skewed towards “not blundering”, which kinda gets run over in a real game. I think there are improvements to the setup that should allow for a more ambitious model, like training on puzzles where passive moves are much worse than the correct
3. Better models? I’ve heard a lot of hate about the LLama 3 models wrt this. Maybe the qwen ones will help me achieve that “aha” moment, or just using an s1-32b or r1 distill is all I need. The issue with finetuning reasoning models is that they think for thousands of tokens (making RL very slow), maybe I can have some early cutoff thing here that make it work with only ~1000 tokens.